r17 vs Hadoop
TweetMatt Nourse, May 15 2012
Back in March the friendly and helpful Pangool developers posted some interesting benchmark results for Hadoop-based tools. There's lots of talk elsewhere about Hadoop scalability but we hear very little about performance so I was excited to learn more about relative performance of these tools. I'd love to see the performance conversation continue. I'm also interested in these benchmarks because for some time I've wanted to compare r17 with Hadoop. These bencharks help because they were run by someone else using a well-known Hadoop distro (so I can't accidentally/subconsciously misconfigure Hadoop) on hardware that I can easily get my hands on (Amazon EC2).
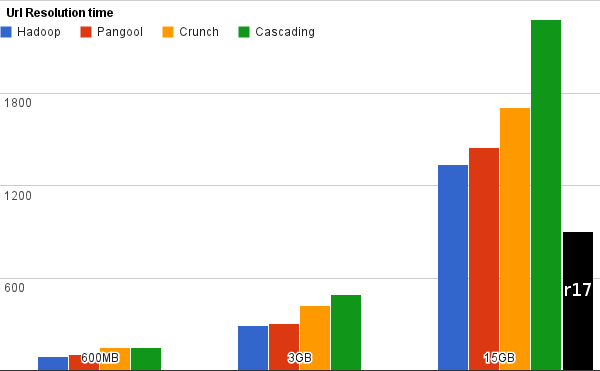
I copied the relevant graphs from the Pangool benchmark results and superimposed my r17 results below. I did 3 runs of each test and averaged the results, though the maximum variation between individual test runs was less than 10%. I only tested the largest-size variant of each test because this is both the most interesting and the least favourable towards r17. R17 ran on only one m1.large machine whereas the other tools in the benchmarks ran on four m1.large slaves plus a master for a total of 5 machines. R17 can scale most operations across machines but its standout feature is the performance it can eke out of a single machine without configuration headaches.
URL Resolution
This test measures join performance. All times are in seconds, smaller is better.
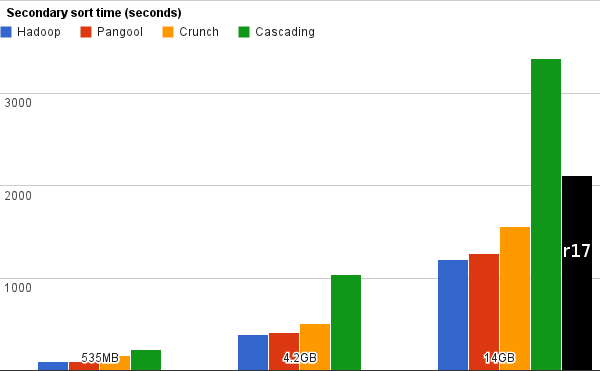
Secondary sort
This test measures sort performance. All times are in seconds, smaller is better.
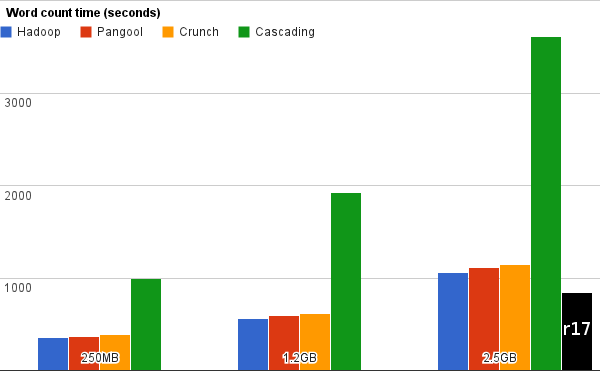
Word count
This test measures basic framework overhead and text processing performance. All times are in seconds, smaller is better.
Code size comparison
This test measures the total number of lines of code for all 3 tests, including comments. Smaller is better.
Conclusions
- r17 is the standout leader in code brevity. This is not surprising because r17 is geared towards data exploration rather than full-blown application development.
- r17 on 1 machine is at least within striking distance of Hadoop on 5 machines. R17 is faster in some cases. EC2's performance can vary so I'd love to see more of this kind of benchmarking.
- r17 can't 'scale to infinity' like Hadoop but r17 is less likely to need large numbers of machines. This is a Big Deal if you're crunching data that's too sensitive to put in the cloud, so you're stuck with whatever machines you have on your LAN. Of course I/O performance is much better on non-cloud machines too. The tests above ran in less than half the time on my pedestrian development machine.
- r17 is especially good for "middle ground" data: too big for easy processing on traditional RDBMSs but not worth the development time and effort of Hadoop. I've processed about 60GB of data with r17 on a single machine without much trouble.
Thanks
Thanks to the Pangool team for their super-responsive support. I had a few questions about their benchmarks and each time I received helpful answers very quickly.
Appendix: Test setup
The Hadoop & friends tests were run by the Pangool team. They describe their setup on their benchmark page. Below is the r17 setup.
- r17 1.5.0
- 1 Amazon EC2 m1.large instance in US West 2b
- 1 Amazon EC2 EBS instance in US West 2b
R17 read test data from EBS and wrote the results back to EBS. The 'Secondary sort' test makes heavy use of /tmp which was mounted on instance storage. I increased the size of /tmp storage to 20GB to accommodate r17's temporary files.
Appendix: r17 test implementations
URL resolution
#!/usr/bin/r17
# Get the url-map file in r17 native format so we can join with it.
io.file.read("url-map-3.txt")
| rel.from_text("([^\t]+?)\t(.*)", "string:url", "string:canonical_url")
| io.file.overwrite("url-map-3.r17_native");
# Do the join and convert the output to TSV.
io.file.read("url-reg-3.txt")
| rel.from_tsv("string:url", "uint:timestamp", "uint:ip")
| rel.join.natural("url-map-3.r17_native")
| rel.select(canonical_url, timestamp, ip)
| rel.to_tsv()
| io.file.overwrite("joined-canonical-urls-3.tsv");
Secondary sort
#!/usr/bin/r17
io.file.read("secondarysort-3.txt")
| rel.from_tsv(
"int:department_id", "string:name_id", "int:timestamp", "double:sale_value")
| rel.order_by(department_id, name_id, timestamp)
| rel.select(department_id, name_id, sale_value)
| rel.group(sum sale_value)
| rel.order_by(department_id, name_id)
| rel.to_tsv()
| io.file.overwrite("secondary-sort-3-result.tsv");
Word count
#!/usr/bin/r17
io.file.read("wordcount-3.txt")
| rel.from_tsv("string:words")
| rel.str_split(words, " ")
| rel.select(words as word)
| rel.group(count)
| rel.order_by(word)
| rel.to_tsv()
| io.file.overwrite("word-count-3-result.tsv");